import yfinance as yf
msft = yf.Ticker("MSFT")
# get stock info
msft.info
# get historical market data
hist = msft.history(period="max")
# show actions (dividends, splits)
msft.actions
# show dividends
msft.dividends
# show splits
msft.splits
# show financials
msft.financials
msft.quarterly_financials
Z3 是一个由 Microsoft Research 开发的定理求解器。它可以用在很多方面,如软/硬件的验证与测试、约束求解、混合系统的分析、安全、生物,以及求解几何等问题[1]。Z3 主要由 C++ 开发,但它支持被 .NET、C、C++、Java、Python 等语言调用。本文使用其 Python binding。
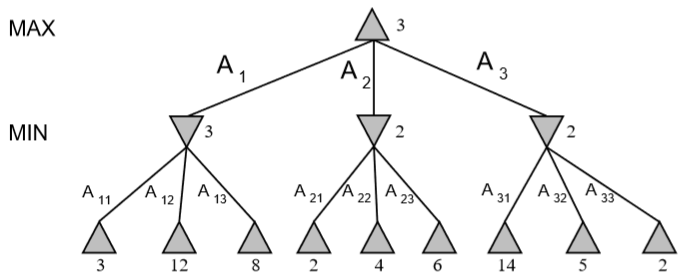
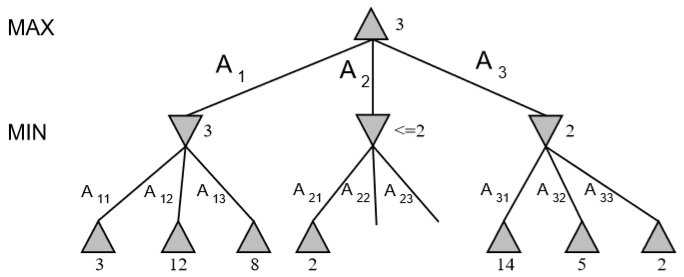
Initialize MAX_VALUE(node,game,-∞,∞)
function MAX_VALUE(state,game,α,β) returns the minimax value of state
inputs: state, current state in game
game, game description
α, the best score for MAX along the path to state
β, the best score for MIN along the path to state
if CUTOFF_TEST(state) then return EVAL(state)
for each s in SUCCESSORS(state) do
α = MAX(α, MIN_VALUE(s,game,α,β))
if α ≥ β then return β
end
return α
function MIN_VALUE(state,game,α,β) returns the minimax value of state
if CUTOFF-TEST(state) then return EVAL(state)
for each s in SUCCESSORS(state) do
β = MIN(β, MAX_VALUE(s,game,α,β))
if α ≥ β then return α
end
return β
在2004年,University of British Columbia 的 D.Lowe 在他的论文 Distinctive Image Features from Scale-Invariant Keypoints 中提出了一个新的算法,Scale Invariant Feature Transform (简称SIFT),它可以提取关键点及计算其描述符。OpenCV的文档指出这篇论文容易理解,推荐阅读。