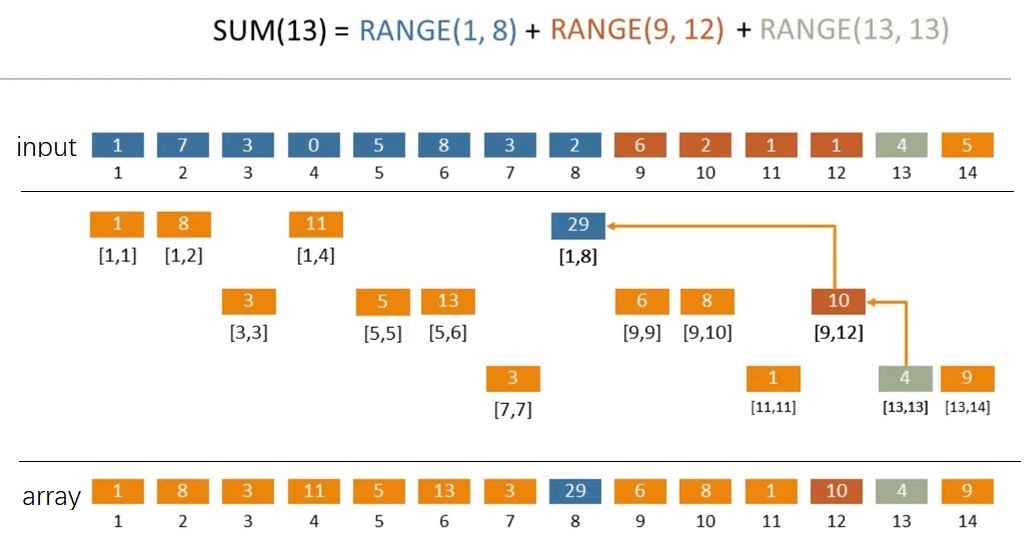
最近工作的项目使我接触到了 Celery 这个任务队列。看了一下官方的文档,感觉设计得还挺 Pythonic,理念也非常简单易懂——类似生产者与消费者。在这里稍微总(fan)结(yi)一下 Celery 的使用方法。
简介
Celery 是一个分布式任务队列,网上也有说是分布式任务调度框架,这里我以官方文档的“Distributed Task Queue”为准。它简单、灵活、可靠,可以处理大量的大量的任务,其主要专注于实时处理,同时也支持计划任务。
为什么要用任务队列?我的理解是,首先方便了任务的分发调度与管理,另外也使调用的过程变得异步(非常适合 web 请求)。
名词解释
- 任务队列(task queue):一种分发任务到不同的线程或机器的方法,其输入为一个任务(task)。
- Worker:实际执行任务的进程,它不断检查任务队列中的新任务并执行。
- Broker:客户端与 worker 通信的中介。客户端发送任务的消息到队列中,broker 把这条消息传递给一个 worker。
入门
如果不考虑进阶用法,5 分钟入门。
安装
首先安装 Celery 并选择 broker。其中 broker 主要支持 RabbitMQ 和 Redis。RabbitMQ 不需要额外依赖,直接执行pip install -U celery安装。 Redis 需要在安装 Celery 时安装附加的依赖:pip install -U "celery[redis]"
RabbitMQ 更为适合生产环境,也稍微大型;Redis 更轻量级,但突然退出时可能丢失数据。为了稍微简单轻量,本文都用 Redis。(如何安装 broker 不在本文内讨论,docker 启动一个最为简单)
新建 Celery 应用
新建一个mytasks.py:
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y
接下来就可以启动 worker 了:(生产环境当然不会这样手动运行,而会把它作为后台程序运行)
$ celery -A mytasks worker --loglevel=info
# 如果不了解上面的命令用法,可查看命令帮助
# celery help
# celery worker --help
调用 task
在当前的目录,运行
>>> from mytasks import add
>>> add.delay(1, 2) # 使用 delay() 来使worker调用这个task
可以得到类似<AsyncResult: fd9cdbe3-bcb3-432a-8d46-67b41243cfed>的返回值,而不会返回 3;这个 3 在 worker 的控制台里可以看到:Task mytasks.add[fd9cdbe3-bcb3-432a-8d46-67b41243cfed] succeeded in 0.0003419s: 3
保存结果
默认情况下,结果是不保存的。如果想保存结果,需要指定 result backend,支持 SQLAlchemy/Django ORM, MongoDB, Memcached, Redis, RPC (RabbitMQ/AMQP) 等。例如app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0'),调用之后就可以查询任务的状态及结果。
>>> result = add.delay(1, 2)
>>> result.ready()
True
>>> result.get(timeout=1)
3
参数配置
简单的参数配置可以直接在代码中修改app.conf,例如:
app.conf.task_serializer = 'json'
对于大型一点的项目,最好专门做一个配置模块。先新建一个 celeryconfig.py:
broker_url = 'pyamqp://xxxx'
result_backend = 'rpc://xxxx'
task_serializer = 'json'
timezone = 'Europe/Oslo'
enable_utc = True
task_annotations = {
'mytasks.add': {'rate_limit': '10/m'}
}
然后通过app.config_from_object('celeryconfig')导入。
稍微深入
Task
Task 有很多选项可以填入,例如用@app.task(bind=True, default_retry_delay=30 * 60),可以修改任务失败后,等待重试的时间。
关于任务的重试,我后来因工作需要,又深入阅读了文档。理想的目标是使一个任务可以自动重试,若重试一定次数仍失败,则发送通知。
首先我看到了acks_late这个参数,它的意思是说一个 task 只有在执行成功后,才给队列 ack(移除)。我试了一下,似乎是不行的,fail 一次之后就没有然后了:
# 是不行的,会被ack
@app.task(acks_late=True)
def add_may_fail_late_ack(x, y):
if random.random() < 0.5:
raise RuntimeError('unlucky')
print('ok')
return x + y
然后是autoretry_for=(XxxException,)参数。这个是最简单的自动重试写法,不需要修改原代码的逻辑,但不够灵活,对于简单的任务比较适用。
最后是功能最全面的写法。首先定义一个自己的 Task,而不使用自带的 Task,因为 Task 可以提供一系列的回调函数(on_xxx)供自定义。例如我可以覆写on_failure方法,在任务超过一定重试次数仍失败时报警。然后是要注意两处地方:一是bind=True,对应的要把def add(x, y)改为def add(self, x, y);二是重试的操作是在业务逻辑手动触发的,且是通过 raise 的方式进行。代码大概是这样子:
class MyTask(Task):
def on_failure(self, exc, task_id, args, kwargs, einfo): # einfo是完整的traceback
print(f'on failure!!! name={self.name}, exc={exc}, task_id={task_id}, args={args}, kwargs={kwargs}')
@app.task(base=MyTask, bind=True, default_retry_delay=5, max_retries=1)
def add_may_fail_custom_retry(self: Task, x, y):
try:
if random.random() < 0.5:
print('fail')
raise RuntimeError('unlucky')
print('ok')
return x + y
except RuntimeError as e:
raise self.retry(exc=e)
上述的代码在第一次遇到RuntimeError时,会等待 5s 重新执行,若仍然遇到RuntimeError(设置了max_retries=1),worker 才会抛出异常。此时会调用 on_failure(),把有用的信息记录下来,例如
on failure!!! name=mytasks.add_may_fail_custom_retry, exc=unlucky, task_id=9ad47d43-7b7f-4d8d-a078-e54934f54d6e, args=[1, 7], kwargs={}
这样就基本达成了预想的效果。其他有关 task 的具体内容,见Tasks文档。
调用 task
前面用到的 delay() 方法是 apply_async() 的简化,但前者不支持传递执行的参数。举例来说,
task.delay(arg1, arg2, kwarg1='x', kwarg2='y')
# 等价于
task.apply_async(args=(arg1, arg2), kwargs={'kwarg1': 'x', 'kwarg2': 'y'})
可见简化了许多。
Countdown 参数可以设置任务至少(可能受 worker busy 或其他原因有所推迟)多少秒后执行;而 eta (estimated time of arrival) 参数可以设置任务至少(原因相同)在具体时刻之后执行:
>>> result = add.apply_async((1, 2), countdown=5) # 至少5秒后执行
>>> result.get() # 阻塞至任务完成
>>> tomorrow = datetime.utcnow() + timedelta(days=1)
>>> add.apply_async((1, 2), eta=tomorrow)
一个任务由于种种原因,延迟太久了,我们可以把它设置为过期,支持输入秒数或一个 datetime:
add.apply_async((10, 10), expires=60) # 如果任务延迟超过60s,将不会被执行
对于一个任务,还可以指定这个任务放到哪个队列中(routing),例如
add.apply_async(queue='priority.high')
使用 -Q 来给 worker 指定监听的队列:
$ celery -A mytasks worker -l info -Q celery,priority.high
像上面这样硬编码 add 的对应 queue 不是太好,更佳的方法是使用 configuration routers。
其他调用 task 的文档,见 Calling Tasks。
函数签名(signature)
对于简单的 task 调用,使用 .delay() 或 .apply_async() 方法一般就已足够。但有时我们需要更高级的调用,例如把任务的返回值用作下一个任务的输入,如果把一系列任务写成串行,就很不推荐了。为此,可以通过函数签名来调用 tasks。
下面给 add() 函数创建一个签名(signature):
>>> add.signature((2, 2), countdown=10)
tasks.add(2, 2)
>>> add.s(2, 2) # 简化,但不能传入task的option,例如countdown
tasks.add(2, 2)
>>> sig = add.signature((2, 2), {'debug': True}, countdown=10) # 完全版
定义了签名后,就可以用sig.delay()来调用这个任务。
签名的一个很重要的功能是它可以定义偏函数,类似 Python 的 functools.partial:
>>> partial = add.s(2) # 不完整的 signature
>>> partial.delay(1) # 1 + 2 注意这个1是填在前面的
偏函数主要的应用场合是各种的原语(Primitives)。这些 primitives 主要包括 group、chain、chord、map、starmap、chunks 等。下面介绍其中几个的用法。
group
group 可以实现任务的并行:
>>> from celery import group
>>> res = group(add.s(i, i) for i in range(10))()
>>> res.get(timeout=1)
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
chain
chain 可以按顺序执行任务,把前一个任务的结果作为接下来的任务的输入。注意偏函数的使用:
>>> from celery import chain
>>> result = chain(add.s('h', 'e'), add.s('llo'), add.s(' world'))()
>>> result.get()
'hello world'
>>> (add.s('h', 'e') | add.s('llo') | add.s(' world'))().get() # 也可以用 | 连接
有关这一部分的更详细内容,见 Canvas: Designing Work-flows。
后台启动
在实际环境中,celery 肯定是以后台服务的方式运行的。文档给出了 systemd、init.d、supervisor 等启动的方式。具体见 Daemonization。
定时任务
定时运行任务的功能由 celery beat 完成。它按设定的周期/时间把任务发送到队列中,并被 worker 执行。对于一个集群的 worker,celery beat 应只有一个,否则任务会重复。
把mytasks.py改成下面所示:
from celery import Celery
from celery.schedules import crontab
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# 每10s执行一次
sender.add_periodic_task(10.0, add.s('hello', ' world'), name='every 10s')
# 按crontab的格式定期执行
sender.add_periodic_task(
crontab(hour='*', minute=5),
add.s('it is', ' xx:05')
)
然后启动 beat:
$ celery -A mytasks beat
可以在 worker 看到每 10s 输出了一次 “hello world”。每个小时的 5 分,都会输出 “it is xx:05”
关于定时任务,具体见 Periodic Tasks。
相关参考
上面只是比较基本的用法。对于更多深入使用中遇到的问题,还是应该参考官网文档。