前言
经本文的评论指出,本文中的代码的原理可能有严重的问题。当作是学习 pytorch 的语法就好了,在修复之前不要用于学术用途。Don’t take it serious!能赚钱的算法都不会公开🤣
目标
学习使用 LSTM 来预测时间序列,本文中使用上证指数的收盘价。
运行环境
Python 3.5+, PyTorch 1.1.0, tushare
数据获取与处理
首先用 tushare 下载上证指数的K线数据,然后作标准化处理。
import numpy as np
import tushare as ts
data_close = ts.get_k_data('000001', start='2018-01-01', index=True)['close'].values # 获取上证指数从20180101开始的收盘价的np.ndarray
data_close = data_close.astype('float32') # 转换数据类型
# 将价格标准化到0~1
max_value = np.max(data_close)
min_value = np.min(data_close)
data_close = (data_close - min_value) / (max_value - min_value)
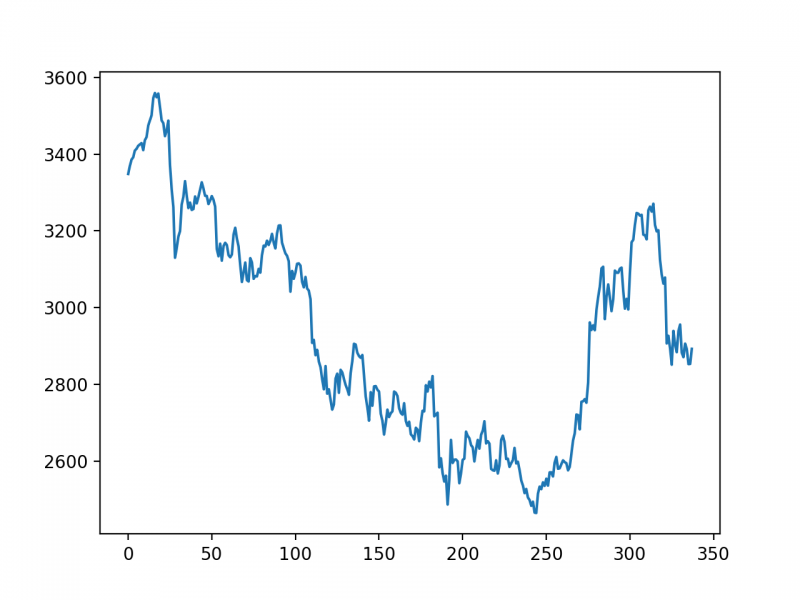
把K线数据进行分割,每 DAYS_FOR_TRAIN 个收盘价对应 1 个未来的收盘价。例如K线为 [1,2,3,4,5], DAYS_FOR_TRAIN=3,那么将会生成2组数据:
第1组的输入是 [1,2,3],对应输出 4;
第2组的输入是 [2,3,4],对应输出 5。
然后只使用前70%的数据用于训练,剩下的不用,用来与实际数据进行对比。
DAYS_FOR_TRAIN = 10
def create_dataset(data, days_for_train=5) -> (np.array, np.array):
"""
根据给定的序列data,生成数据集
数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。
也就是说用days_for_train天的数据,对应下一天的数据。
若给定序列的长度为d,将输出长度为(d-days_for_train+1)个输入/输出对
"""
dataset_x, dataset_y= [], []
for i in range(len(data)-days_for_train):
_x = data[i:(i+days_for_train)]
dataset_x.append(_x)
dataset_y.append(data[i+days_for_train])
return (np.array(dataset_x), np.array(dataset_y))
dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN)
# 划分训练集和测试集,70%作为训练集
train_size = int(len(dataset_x) * 0.7)
train_x = dataset_x[:train_size]
train_y = dataset_y[:train_size]
# 将数据改变形状,RNN 读入的数据维度是 (seq_size, batch_size, feature_size)
train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN)
train_y = train_y.reshape(-1, 1, 1)
# 转为pytorch的tensor对象
train_x = torch.from_numpy(train_x)
train_y = torch.from_numpy(train_y)
定义网络、优化器、loss函数
import torch
from torch import nn
class LSTM_Regression(nn.Module):
"""
使用LSTM进行回归
参数:
- input_size: feature size
- hidden_size: number of hidden units
- output_size: number of output
- num_layers: layers of LSTM to stack
"""
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, _x):
x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
x = x.view(s*b, h)
x = self.fc(x)
x = x.view(s, b, -1) # 把形状改回来
return x
model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
训练
for i in range(1000):
out = model(train_x)
loss = loss_function(out, train_y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (i+1) % 100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(i+1, loss.item()))
测试
import matplotlib.pyplot as plt model = model.eval() # 转换成测试模式 # 注意这里用的是全集 模型的输出长度会比原数据少DAYS_FOR_TRAIN 填充使长度相等再作图 dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size) dataset_x = torch.from_numpy(dataset_x) pred_test = model(dataset_x) # 全量训练集的模型输出 (seq_size, batch_size, output_size) pred_test = pred_test.view(-1).data.numpy() pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同 assert len(pred_test) == len(data_close) plt.plot(pred_test, 'r', label='prediction') plt.plot(data_close, 'b', label='real') plt.plot((train_size, train_size), (0, 1), 'g--') plt.legend(loc='best') plt.show()
结果与总结
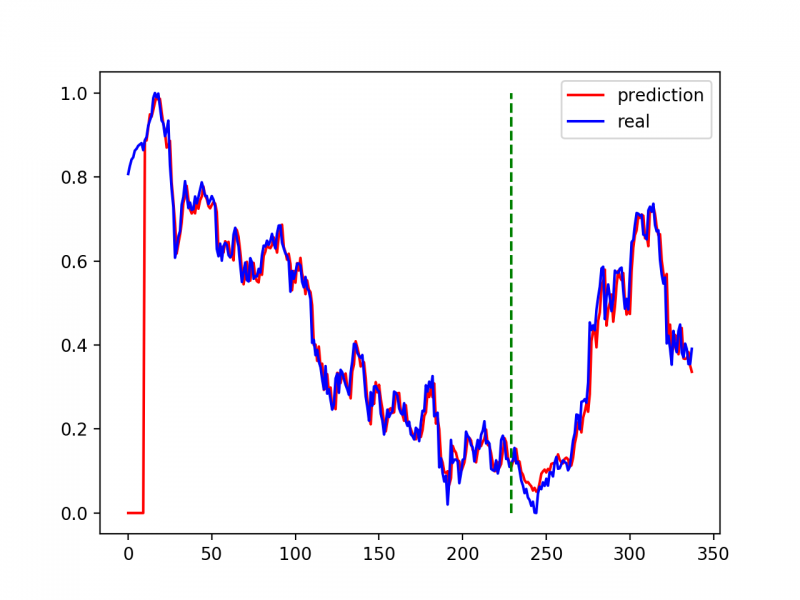
本文的代码是参考网上的文章写的,没有专门调超参数。左边的红线在一开始都是0,是因为输入到模型的经过预处理的数据比原数据要短DAYS_FOR_TRAIN,网上的一些实现没有进行补全( 如文末的“相关参考1、2” ),会导致红线和蓝线有水平偏移。在我简单地修复了水平偏移后,可以发现在绿色线左边的训练集部分,拟合效果是非常的好。这是正常的,因为在训练集中过拟合很正常。但是,在绿线右侧,效果也相当好(在“相关参考3”中,甚至靠前几年的数据“预测”到了最近两年的数据),这似乎不太正常——真有这样的准确率,还需要上学/上班吗?
我觉得,这应该是模型在eval的时候,数据输入的问题。在pred_test = model(dataset_x) 这里,把全量的数据喂给了模型——这已经把真正的价格给了模型了,这应该是错误的。
我可以随便给一个模型,用今天的价格预测明天的价格,具体实现就是明天的价格=今天的价格(再加上一点微小的偏离?),放在这样一个这样的一个scale里面,保证看起来也很精确。但这对实际操作是没有指导价值的。
回到刚才的 LSTM 模型,它是根据前 n 天的价格预测下一天的价格。在这么多个“下一天的价格”里面,有多少是准确的(只考虑涨/跌),有多少的偏离,还需要进一步的探索。
相关参考
- https://github.com/L1aoXingyu/code-of-learn-deep-learning-with-pytorch/tree/master/chapter5_RNN/time-series
- https://blog.csdn.net/baidu_36669549/article/details/85595807
- https://blog.csdn.net/a19990412/article/details/85139058
最后附完整代码
#!/usr/bin/python3
# -*- encoding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
import torch
from torch import nn
DAYS_FOR_TRAIN = 10
class LSTM_Regression(nn.Module):
"""
使用LSTM进行回归
参数:
- input_size: feature size
- hidden_size: number of hidden units
- output_size: number of output
- num_layers: layers of LSTM to stack
"""
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, _x):
x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
x = x.view(s*b, h)
x = self.fc(x)
x = x.view(s, b, -1) # 把形状改回来
return x
def create_dataset(data, days_for_train=5) -> (np.array, np.array):
"""
根据给定的序列data,生成数据集
数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。
也就是说用days_for_train天的数据,对应下一天的数据。
若给定序列的长度为d,将输出长度为(d-days_for_train+1)个输入/输出对
"""
dataset_x, dataset_y= [], []
for i in range(len(data)-days_for_train):
_x = data[i:(i+days_for_train)]
dataset_x.append(_x)
dataset_y.append(data[i+days_for_train])
return (np.array(dataset_x), np.array(dataset_y))
if __name__ == '__main__':
data_close = ts.get_k_data('000001', start='2018-01-01', index=True)['close'].values # 取上证指数的收盘价的np.ndarray 而不是pd.Series
data_close = data_close.astype('float32') # 转换数据类型
plt.plot(data_close)
plt.savefig('data.png', format='png', dpi=200)
plt.close()
# 将价格标准化到0~1
max_value = np.max(data_close)
min_value = np.min(data_close)
data_close = (data_close - min_value) / (max_value - min_value)
dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN)
# 划分训练集和测试集,70%作为训练集
train_size = int(len(dataset_x) * 0.7)
train_x = dataset_x[:train_size]
train_y = dataset_y[:train_size]
# test_x = dataset_x[train_size:] # 暂时没有用到
# test_y = dataset_y[train_size:] # 暂时没有用到
# 将数据改变形状,RNN 读入的数据维度是 (seq_size, batch_size, feature_size)
train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN)
train_y = train_y.reshape(-1, 1, 1)
# test_x = test_x.reshape(-1, 1, DAYS_FOR_TRAIN)
# 转为pytorch的tensor对象
train_x = torch.from_numpy(train_x)
train_y = torch.from_numpy(train_y)
# test_x = torch.from_numpy(test_x)
model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
for i in range(1000):
out = model(train_x)
loss = loss_function(out, train_y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (i+1) % 100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(i+1, loss.item()))
# torch.save(model.state_dict(), 'model_params.pkl') # 可以保存模型的参数供未来使用
# for test
model = model.eval() # 转换成测试模式
# model.load_state_dict(torch.load('model_params.pkl')) # 读取参数
# 注意这里用的是全集 模型的输出长度会比原数据少DAYS_FOR_TRAIN 填充使长度相等再作图
dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size)
dataset_x = torch.from_numpy(dataset_x)
pred_test = model(dataset_x) # 全量训练集的模型输出 (seq_size, batch_size, output_size)
pred_test = pred_test.view(-1).data.numpy()
pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同
assert len(pred_test) == len(data_close)
plt.plot(pred_test, 'r', label='prediction')
plt.plot(data_close, 'b', label='real')
plt.plot((train_size, train_size), (0, 1), 'g--') # 分割线 左边是训练数据 右边是测试数据的输出
plt.legend(loc='best')
plt.savefig('result.png', format='png', dpi=200)
plt.close()
这样做是错误的,原因在于你在预处理的时候把数据做了归一化处理,但是在预测的时候缺没有对数据做阈值的还原: 举个例子,如果原本的量纲是1000的话,在0-1范围内偏差0.01,那么实际的误差就已经是10了.所以你画出来的图看着拟合的好,其实是把偏差进行了压缩导致的.
嗯,有一定的道理,发本文的目的之一就是探讨一下网上的一些文章的不准确之处。虽然本文的也是不准确的
大佬,最后出图如何只出测试数据输入预测图呢?就是绿色虚线右边的那部分
不是很懂你提的问题,
plt.plot(pred_test, 'r', label='prediction')这里的 pred_test 是所有的model输出了,做一下数组切片就可以了?就是最后的图只是在测试集上预测输出图,只要虚线右边的,不要左边的
对数据切片,只输入虚线右边的数据就可以了
从图形上看,归一化后的预测图和还原后的预测图没任何区别,但是从数据看,归一化后的偏差也确实压缩了。
确实有所影响
大佬,最后出图如何只出测试数据输入预测图呢?就是绿色虚线右边的那部分
俩种办法
(1)测试的时候不用全部数据集,只用测试的数据
(2)测试用了全部数据集,在显示的时候不要显示全部预测值,比如230到350是你的测试集,那么显示的时候就用plt.plot(pred_test[230:350], ‘r’, label=’prediction’)
想了一下,好像第二种才是对的,因为LSTM有内部的状态。。。?
看着很准,其实放大看会有明显的滞后性,实际应用的时候帮助不大
没错,就是这样的,现实没有这么简单
多变量时间预测可以改么,我已经写好了数据预处理,就是不知道
INPUT
[
[1,2,3],[2,3,4],[4,5,6]….[m,n,p]
[1,2,3],[2,3,4],[4,5,6]….[m,n,p]
…
]
OUT
[
[1,2,3]
[1,2,3]
…
]
这种数据pytorch可以直接用么
可以加QQ交流下么619511821
跑的时候,为什么图没出来
你好!我仔细阅读了你的代码,感觉你对shape的处理有点问题,导致整个模型的构造可能完全是错的。。。
假设一共有500天数据,你的每个样本包含前10天的价格,希望用它们预测下一天价格,这样你一共能抽取490个样本,由于LSTM的输入shape是(seq_size, batch_size, feature_size),你应当给LSTM传进去一个(10,490,1)的数组,而你的代码传进去的是一个(490,1,10)的数组,这就表示你实际上只有1个sample,它的序列长度是490,每个step传进去一个长度为10的input
https://blog.csdn.net/a19990412/article/details/85139058
你列的这个参考资料,里边第一条评论和我应该是一个意思,都是说shape上有问题
多谢你的指出,我已经更新了本文的前言。我以后也会认真学习LSTM、pytorch的相关知识、原理
这个输入(seq_size, batch_size, feature_size), 到底应该是多少?希望作者百忙之中能说明下, 万分感谢