每一个 node 的返回值都是整个 state 的子集。也就是说每个 node 都可以改变整个状态。
然后 langgraph 会按照 state 的定义, partial update 整个状态,如果定义的字段是累加的,那么就会加起来,否则就是覆盖的。
后记:现在有了 LLM,确实不用写很多博文了,问 AI 就好
每一个 node 的返回值都是整个 state 的子集。也就是说每个 node 都可以改变整个状态。
然后 langgraph 会按照 state 的定义, partial update 整个状态,如果定义的字段是累加的,那么就会加起来,否则就是覆盖的。
后记:现在有了 LLM,确实不用写很多博文了,问 AI 就好
FastAPI 经常号称是非常快的框架,因为它大量使用 async。对于一些 IO 密集型的任务,是有一些坑要处理的,不然整个 async 就被堵住了。这个处理还是比较简单的,按官网文档的说法,
如果你的应用程序不需要与其他任何东西通信而等待其响应,请使用
async def
如果你不清楚,使用def就好
那如果是 CPU 密集型的任务呢?这是工作中同事遇到的问题。
用def的办法就不行了——会把线程池堵住。
下面 4 种写法,有 2 种都可以解决这个问题,都是进程池的方案。
from concurrent.futures import ProcessPoolExecutor
import asyncio
import time
from fastapi import FastAPI
import uvicorn
app = FastAPI()
def fib(n: int) -> int:
if n == 1 or n == 2:
return 1
return fib(n-1) + fib(n-2)
def some_cpu_work() -> int:
return fib(36) # 大概1s
# 通用配置:20个并发,同时请求
@app.get("/test1")
async def test1():
""" async定义+直接计算 排队 27s CPU占用1核心 """
data = some_cpu_work()
print(data)
return data
@app.get("/test2")
def test2():
""" 普通定义+直接计算 自带线程池 依然27s CPU占用1核心 """
data = some_cpu_work()
print(data)
return data
#################################### 开一个进程池
process_pool_executor = ProcessPoolExecutor(max_workers=4)
@app.get("/test3")
def test3():
""" 普通定义+进程池 8s CPU占用4核心 """
task = process_pool_executor.submit(some_cpu_work)
data = task.result()
print(data)
return data
@app.get("/test4")
async def test4():
""" async定义+交给进程池 8s CPU占用4核心 """
data = await asyncio.get_running_loop().run_in_executor(process_pool_executor, some_cpu_work)
print(data)
return data
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000)
具体来说,20 个请求同时请求,这 20 个请求在 4 种写法的结果如下:(其中第2种堵住了自带线程池的结果最出乎意料)
阅读更多…首先说明,这个运行其他 Python 版本并不是影响 jupyter notebook 的 Python 版本,而是在 notebook 中通过!python xxxxx.py执行我上传的脚本所使用的 Python。
撰写本文时,Colab 的 Python 是 3.7。
我的项目中用到了一些 3.8、3.9 的新语法,所以没法在 Colab 上面跑,但我也不想把这些语法改成旧的,所以只能在 Colab 上升级了。
经过一番摸索,发现最靠谱的方法是在 apt 中安装新版 Python,然后全程使用 venv,而不用系统的 Python。系统的 Python 总是遇到 pip 安装库时的各种奇怪问题。
所以,在 notebook 中的命令如下:
!sudo apt-get update -y !sudo apt-get install python3.9 python3.9-distutils python3.9-venv !python3.9 --version !python3.9 -m venv venv
之后运行 pip 安装第三方库、运行 python xxxx.py 时,都使用如下方式:
!venv/bin/pip install xxx_library !venv/bin/python xxx.py
本文通过实际项目的经历,经过搜索与比较,终于找到了好用的 Python 序列化库:marshmallow。
它拥有类似 django 的语法,支持详细的自定义设置,适合各种各样的序列化/反序列化情景。
我们都知道,Python 自带了一些序列化的库,例如 json、pickle、marshal 等。现在的问题是,要向一个 HTTP 服务器提交一个 POST 请求,附带一个 JSON 作为 payload,假设这个 payload 是这样的:
{
"name": "abc",
"price": 1.23456,
"date": "2021-06-26"
}
那么,它对应的 Python 定义是
from dataclasses import dataclass
import datetime
@dataclass
class Item:
name: str
price: float
date: datetime.date
所以,这个 POST 请求会是这样发送的:
import json
import requests
item = Item('abc', Decimal('1.23456'), '2021-06-26')
requests.post(url, data=json.dumps(item))
这样一跑,马上给报错:TypeError: Object of type Item is not JSON serializable。嗯?????怎么报错了?才知道 Python 自带的 json 库不支持序列化一个自定义的 class,仅仅支持那几个 Python 内置的类,如 dict, str, float, list, bool。对此,网上是有一些解决方法,但其实都是妥协之举:如果服务器返回一个 {"name": "abc","price": 1.23456,"date":"2021-06-26"},能方便地反序列化成实例么?
遇到这种问题,首先就想起“不要自己造轮子”的原则。Python 作为一门非常成熟的语言,就没有什么 pythonic 的解决方案?然后我去百度、Google,似乎还真没有,marshmallow 已经是我能找到的最好的了。
手上还有 JVM 的项目,可以用 jackson/fastjson 等库,那才是方便啊,类型传进去后,正反序列化一气呵成。
如果自己给这个类写一个 to_json() 方法,手动构造一个 dict 呢?想想还是不行,如果未来要修改这个类的属性,那么还得对应改。什么?你说连这个类都不要了,post 的时候直接现场构造一个 dict?这绝对是在给自己挖坑啊。
所以,marshmallow 赶紧学起来。
最重要的,是定义 schema。对于刚才的 Item 类,对应的 schema 会这样写:
@dataclass
class Item:
name: str
price: Decimal
date: datetime.date
# 对于其他的所有 fields, 可以参考文档
# https://marshmallow.readthedocs.io/en/stable/marshmallow.fields.html#api-fields
from marshmallow import Schema, fields
class ItemSchema(Schema):
name = fields.String()
price = fields.Decimal()
date = fields.Date()
如果以前接触过 django,应该对这种写法很熟悉,不过不熟悉也没关系。
然后,就可以用 dump() 序列化了。
item = Item('abc', Decimal('1.23456'), datetime.date(2021, 6, 26))
schema = ItemSchema()
result_obj = schema.dump(item)
print(result_obj)
# 会输出 {'price': Decimal('1.23456'), 'name': 'abc', 'date': '2021-06-26'}
可以看到,在定义好的 schema 的帮助下,item 实例变成了一个 dict。
如果想输出一个字符串呢?可以把 schema.dump 换成 schema.dumps。(不过由于 price 是一个 Decimal 实例,而自带的 json 不支持 Decimal 会报错,可以考虑另外装一个 simplejson 库来解决。这个问题在后文会再讲到)
使用 load() 进行反序列化:
input_data = { 'name': 'abc', 'price': Decimal('1.23456'), 'date': '2021-06-26'}
load_result = schema.load(input_data)
print(load_result)
# 输出 {'name': 'abc', 'date': datetime.date(2021, 6, 26), 'price': Decimal('1.23456')}
注意到 date 属性变成了一个 Python 的 datetime.date 实例,这是我们希望的。
这里只是反序列化成了一个 dict,那么怎样才能返回一个真正的 Item 实例?可以给 schema 添加一个返回 Item 的方法,并打上 post_load 的注解(装饰器)。
from marshmallow import Schema, fields, post_load
class ItemSchema(Schema):
name = fields.String()
price = fields.Decimal()
date = fields.Date()
@post_load
def make_item(self, data, **kwargs):
return Item(**data)
result_obj = schema.dump(item)
print(result_obj)
# 返回 Item(name='abc', price=Decimal('1.23456'), date=datetime.date(2021, 6, 26))
可以,有点样子了。
既然有了 schema,当然可以顺便在 load 时做校验了。例如输入的字段有没有多,有没有缺,属性的类型对不对,值的范围有没有超,哪些属性可以填 None(null)等等。这里不再赘述,见文档。
Marshmallow 库自带的一些类型可能不够满足需求,例如想加一个 省份、身份证 什么的,用字符串的话好像感觉欠缺了一点校验。而刚才提到的 Decimal 比较难处理,我觉得也可以用自定义字段来解决。
例如,可以用 Method 字段来自定义正反序列化时所使用的方法。
class ItemSchema(Schema):
name = fields.String()
price = fields.Method('price_decimal_2_float', deserialize='float_2_decimal')
date = fields.Date()
@post_load
def make_item(self, data, **kwargs):
return Item(**data)
def price_decimal_2_float(self, item: Item):
return float(item.price)
def float_2_decimal(self, float):
return decimal.Decimal(str(float))
这样就可以正常用 dumps(), loads() 了:
result_str = schema.dumps(item)
print(result_str)
# {"date": "2021-06-26", "name": "abc", "price": 1.23456}
input_str = '{"date": "2021-06-26", "name": "abc", "price": 1.23456}'
load_result = schema.loads(input_str)
print(load_result)
# Item(name='abc', price=Decimal('1.23456'), date=datetime.date(2021, 6, 26))
太棒了,输入的 JSON 的 date 和 price,在反序列化后,自动变成了 datetime.date 和 Decimal。
Marshmallow 的核心是 schema,数据类型、校验等都记录在 schema 中,从而支持复杂对象的序列化和反序列化。如果说它有什么缺点,那必须是它仍然需要专门定义一个 schema 才能使用。如果是 JVM 系列的 jackson 等库,可以直接使用 data class 作为 model/schema,额外的配置通过注解等方式引入,这样会少一个对应的 schema 类。marshmallow 的做法使类的数量双倍了。总体来说,它仍然是不造轮子的情况下的好选择。
至于更深入的用法,还是需要参考官方文档,见文末。
这个问题困扰我多时,曾尝试多个方案未果,今天终于搜到了正确的解决方法,记录下来。
我的网络拓扑: 外部 → docker的nginx → docker的gunicorn → flask
Flask 代码中的 redirect(url_for('login')) 会跳回 http 的登录页面。
我也不想给每个 url_for() 添加强制 https 的参数。
from werkzeug.middleware.proxy_fix import ProxyFix from flask import Flask app = Flask(__name__) app.wsgi_app = ProxyFix(app.wsgi_app)
最近在工作中需要在 Python 程序中读写 Redis。之前在自己的项目中,用的是 redis-py ——也是最广为人知的客户端。
不过,它相当难用,几乎就是原生的 Redis 命令,在大一点的项目中,写一堆 Redis 命令,我估计是受不了的。而我在工作的其他 Java/JVM 项目里,用的是经过抽象封装后的库 Redisson,使用的体验就很舒服。
那么,在 Python 环境,如果不用 redis-py,用什么库好呢,还是自己造轮子?
在官网的客户端列表中可以找到,除了 redis-py,Python 另外还有 walrus 这个推荐的客户端。直接点进去,了解到它支持很 pythonic 风格的 Hash、List、Set、Sorted Set 等容器,足以满足我的使用需求,就用它了~
附其代码样例:
>>> h = db.Hash('charlie')
>>> h['age'] = 31
>>> print(h)
<Hash "charlie": {'age': '31'}>
FIX 协议开发(1):协议介绍及开发方案(本文)
FIX 协议开发(2):QuickFIX/J 入门
FIX 协议开发(3):QuickFIX/J 实战经验小结
公司因业务需要,准备接入 FIX 协议。在调研过程中,我发现中文的 FIX 协议相关资料不太多,准备边学边记录,预计会写 3 篇左右。
FIX(Financial Information eXchange Protocol,金融信息交换协议)是由国际FIX协会组织提供的一个开放式协议,目的是推动国际贸易电子化进程,在各类参与者之间,包括投资经理、经纪人、买方、卖方建立起实时的电子化通讯协议。
FIX协议的目标是把各类证券金融业务需求流程格式化,成为一个可用计算机语言描述的功能流程,并在每个业务功能接口上统一交换格式,方便各个功能模块的连接。
FIX 协议消息均由多个 “key=value” 组成。其中 key 可以是协议规定的字段,或自定义字段。协议规定的key可查询 FIX 协议字典,【不同版本的 FIX 协议均有其字典,用于开发的库一般也有自带;也可参考第三方,如 wireshark】例如 8 代表 begin string,34 代表消息的序列号,52 代表时间戳等。自定义字段不与规定的 key 重复,供金融机构定制,开发时需要向对应金融机构获取其专有字段的字典。只要有了对应的字典,就可以读懂 FIX 数据包的内容。
一般来说,一个 消息由“头部 + 消息体 + 尾部”构成。头部包含一些必要的字段,例如 BeginString (8)、BodyLength (9)、MsgType (35)、MsgSeqNum (34)、SenderCompID (49) 等,尾部包含的必要字段是 CheckSum (10)。
FIX 登陆消息示例(假设”^”是分隔符):
8=FIX.4.3^9=65^35=A^34=1^49=TESTACC^52=20130703-15:55:08.609^56=EXEC^98=0^108=30^10=225^
对照字典可知,BeginString (8) 是 FIX.4.3;BodyLength (9) 是 65 字节;MsgType (35) 是 A,A 对应 logon 操作;MsgSeqNum (34) 是 1,即这是我方发送的第 1 个消息。
有关更详细的协议介绍,可参考 https://blog.51cto.com/9291927/2536105
由上面的示例可以发现,FIX 协议十分简单。可以不需要依赖第三方库,手动查字典构造消息8=FIX.4.3^9=65^35=A^34=1<省略>
再通过标准的 socket 通信,即可完成交互。
这个方案自由度最高,不依赖底层开发语言,但开发流程与查字典较为繁琐,后续维护也不太方便。
simplefix 是一个 FIX 协议的简易实现。它使用户可以方便地任意构造 FIX 消息,非常适合学习、测试协议。但这个库不包含任何网络收发、FIX 异常处理等功能模块。因此,开发 FIX 客户端时,我使用该库构造数据包,然后通过标准 socket 发送,再分析其网络底层交互。
示例:发送 logon 消息的代码
import socket
import time
import simplefix
from simplefix.constants import (ENCRYPTMETHOD_NONE, MSGTYPE_LOGON,
TAG_BEGINSTRING, TAG_CLIENTID,
TAG_ENCRYPTMETHOD, TAG_HEARTBTINT,
TAG_MSGSEQNUM, TAG_MSGTYPE, TAG_SENDER_COMPID,
TAG_SENDING_TIME, TAG_TARGET_COMPID)
HOST = '1.2.3.45'
PORT = 9000
CLIENT_ID = 12345678
PASSWORD = 'mypassword'
seq_num = 1 # 需维护msg sequence number,每次发送后加1
if __name__ == "__main__":
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1) # 长连接
sock.connect((HOST, PORT))
# logon
msg_logon = simplefix.FixMessage()
msg_logon.append_pair(TAG_BEGINSTRING, 'FIX.4.2')
msg_logon.append_pair(TAG_MSGSEQNUM, seq_num) # 需维护msg sequence number,每次发送后加1
msg_logon.append_pair(TAG_SENDER_COMPID, 'FIXTEST001')
msg_logon.append_utc_timestamp(TAG_SENDING_TIME)
msg_logon.append_pair(TAG_TARGET_COMPID, 'TESTENV')
msg_logon.append_pair(TAG_MSGTYPE, MSGTYPE_LOGON) # 类型
msg_logon.append_pair(TAG_ENCRYPTMETHOD, ENCRYPTMETHOD_NONE)
msg_logon.append_pair(TAG_HEARTBTINT, 30)
msg_logon_buffer = msg_logon.encode()
sock.send(msg_logon_buffer)
print('seq', seq_num, 'sent')
seq_num += 1
time.sleep(1)
sock.close()
QuickFix 是全功能的 FIX 开源引擎,目前很多 Fix 解决方案都是根据或参考 QuickFix 实现的。目前(2020年10月)它有 C++、Python、Java、.NET、Go 和 Ruby 共 6 种语言的实现/接口。
根据我司的情况,选择其中的 Java 实现 QuickFIX/J 进行下一步开发。其使用方法,将在下一篇文章继续。
树状数组是一个能高效处理数组①更新、②求前缀和的数据结构。它提供了2 个方法,时间复杂度均为O(log n):
如果只追求第 1 点,即快速修改数组,普通的线性数组可满足需求。但对于 range sum(),需要O(n)。
如果只追求第 2 点,即快速求 range sum,使用前缀数组的效果更好。但对于 add() 操作,则需要O(n),所以只适合更新较少的情况。
树状数组则处于两者之间,适合数组又修改,又获取区间和的情景。
树状数组的思想是怎样的呢?
假设有一个数组 [1, 7, 3, 0, 5, 8, 3, 2, 6, 2, 1, 1, 4, 5],想求前 13 个元素的和。那么,
13 = 23 + 22 + 20 = 8 + 4 + 1
前 13 个数的和等于【前 8 个数的和】+【接下来 4 个数的和】+【接下来 1 个数的和】,即 range(1, 13) = range(1, 8) + range(9, 12) + range(13, 13)。如果有一种方法,可以保存 range(1, 8)、range(9, 12)、range(13, 13),那么计算这个区间和就可以加快了。
这里给出已经计算好的结果(即最下面的 array 层)。例如 array[8] 是 29,往上可以找到 29 对应的是 [1,8],即 range(1, 8) = array[8]。同理,range(9, 12) = array[12],range(13, 13) = array[13]。
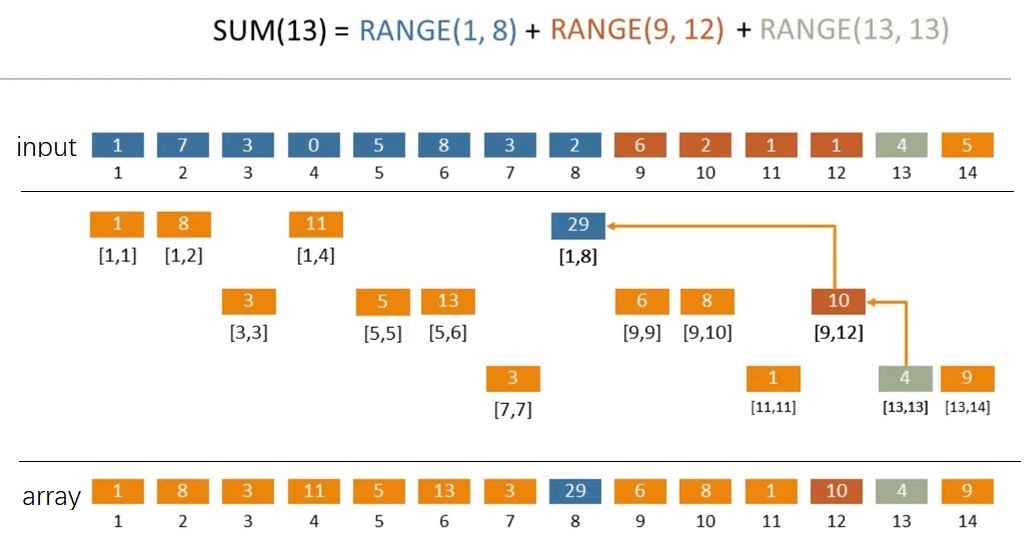
由此图可以发现,虽然它的英文是含有 Tree,中间的部分看起来也是树状的,但是最终用到的 array 是线性的数组(太好了,复杂程度大减)。
那中间这 3 层是怎么来的呢?——需要从上到下,从左到右看。
首先计算 [1, 1] 的和,然后计算 [1, 2] 的和,然后计算 [1, 4]、[1, 8] 的和,每次乘 2,直到越界([1, 16] 越界),这里分别算出来了1、8、11、29。
然后是第二层,从空缺的位置继续,这里的“界”不是整个数组的最大值,而是所有上层中下一个非空缺的位置。计算 [3, 3] 的和,[3, 4] 不用算,因为越界了。然后计算 [5, 5] 的和,接下来是 [5, 6] 的和,[5, 8] 越界不用算。
第三层也是类似,然后发现填完了。
以上可以帮助理解 result 数组中各值的来源,实际建立时有更简洁的做法。至于为什么是这样定义,可以另外找找资料,我看起来这有点像“分形”的感觉。
阅读更多…跳跃列表是一种随机数据结构。它使得包含 n 个元素的有序序列的查找、插入、删除操作的平均时间复杂度都是 O(log n)。(注意关键词有序,如果不需要有序,也不需要用到跳跃列表;数据量大时,时间复杂度退化到较慢的概率微乎其微)
| 平均 | 最差 | |
| 搜索 | O(log n) | O(n) |
| 插入 | O(log n) | O(n) |
| 删除 | O(log n) | O(n) |
| 空间 | O(n) | O(n log n) |
跳跃列表是通过维护一个多层的链表实现的。每一层链表中的元素的数量,在统计上来说都比下面一层链表元素的数量更少。也就是说,上层疏,下层密,底层数据是完整的,上面的稀疏层作为索引——这就是链表的“二分查找”啊。
一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。
Wikipedia 的道理就讲到这里,我不希望把本文写得难懂。说好的一图流就能领悟呢?其实我有点标题党,本文不止一幅图,但是核心的图只有一幅,上图(来自 Wikipedia):
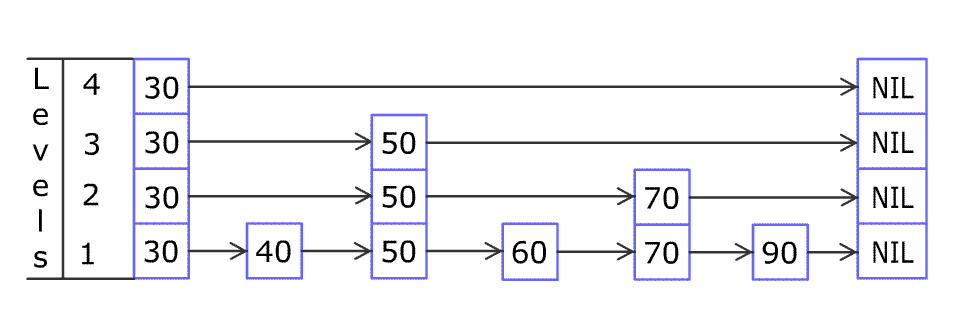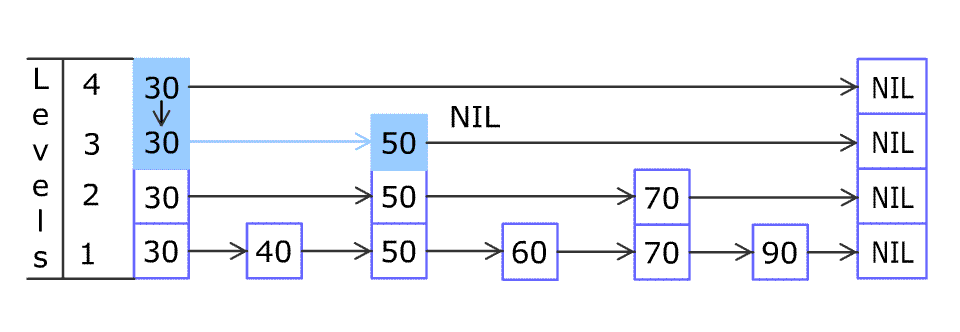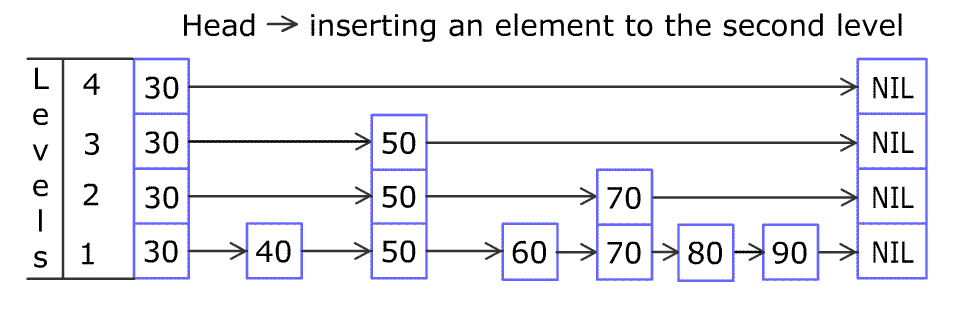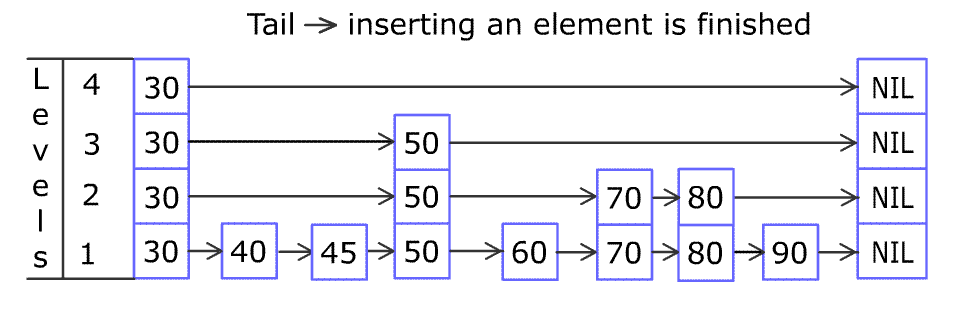
请多次认真观看插入节点的全过程 gif。我看完之后,就觉得自己可以实现出来了(虽然后来实际开发调试了很多次)。
例如想在上图中所示的跳跃列表中插入 80,首先要找到应该插入的位置。
首先从最稀疏的层的 30 开始,把当前位置设置为顶层的 30。
80 比当前位置右边的 NIL 小,所以把当前位置移到下一层的 30;
80 比当前位置右边的 50 大,所以把当前位置右移到 50;
80 比当前位置右边的 NIL 小,所以把当前位置移到下一层的 50;
80 比当前位置右边的 70 大,所以把当前位置右移到 70;
80 比当前位置右边的 NIL 小,所以把当前位置移到下一层的 70;(当前位置已到达底层)
之后用 80 不断与右边的节点比较大小,右移至合适的位置插入 80 节点。(底层插入完毕)
接下来用随机决定是否把这个 80 提升到上面的层中,例如图中的提升概率是 50%(抛硬币),不断提升至硬币为反面为止。
上面一段描述了 gif 中插入 80 的搜索和插入过程。那么,代码如何实现?右移和下移的逻辑很浅显,那么重点就在如何提升节点到上层的逻辑。
阅读更多…